![[Home]](/~megera/oddmuse/zen3.gif)
Scalable indexing of very big sky catalogues in open-source relational database - PostgreSQL. We advocate the adoption of PostgreSQL by astronomical community.
There is a common opinion that good pixelization method should satisfy 3 conditions ( see Desiderata):
Do we really need them for database indexing ? Not at all. We need simple numbering scheme, so that for any given point we could easily calculate the number of "pixel", this is what HealPix provides and lacks HTM. Also, we need simple pixel shape for easy geometrical calculation, like HTM's triangles, while HealPix pixel has curved shape which complicates geometrical calculation.
Our method is a hybrid of HTM and HealPix and in a nutshell is *"The quadrilaterlized spherical cube"*, which was used in COBE ( see details in SphereCube). Special numbering scheme keeps spatial closiness, so we could use standard Btree index provided by PostgreSQL for searching pixels.
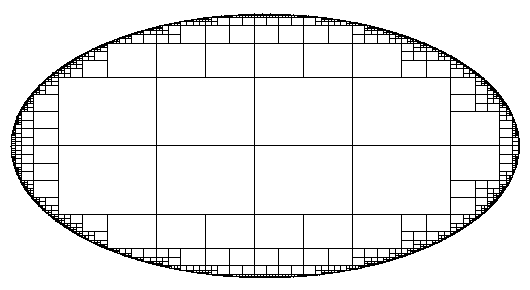
|
| Quad-tree pixelization of the circle of cone search ((42,0), radius 1arc second) on cube face. Notice, regular shapes of pixels and circle projected to ellipse. |
The main feature of astronomical databases, the cone search was implemented by following way:
Also, we could use CLUSTER feature to store database rows on disk according index, which greatly increases performance of fetching tuples.
Finally we want to underline two important facts about our scheme:
Test run consists of desorted (to exclude caching) cone queries over USNO-A1 catalogue (>500,000,000 rows), which cover all sky for Q3C (our method), two-column (ra,dec) btree index and Rtree (box). We run queries for set of radii (0.1, 0.2, 0.4, 0.8, 1.6, 3.2) degrees, total 1800 queries for each run.
It's always difficult to provide fair comparison because of influence of many factors, such as system caching, system load, etc. So, we present some timings and mostly concentrate on blocks IO statistics, provided by PostgreSQL statistic collector
We use spare hardware kindly provided by Scientific Network project, which is DUAL Xeon 2.4 GHz, 1Gb RAM, 160Gb IDE disk ( IBM / Hitachi HDS722516VLAT80, 8.5 ms average seek time, 4.7 ms latency average time, see details ), Linux 2.6.7 optimized for Web applications. We configured separate pg superuser and installed 8.01 version in different location (there is primary "production" 7.4.6 PostgreSQL server). Because of tight conditions we couldn't fully optimized our backend, below some parameters from postgresql.conf:
Database structure
wsdb=# \d usno
Table "public.usno"
Column | Type | Modifiers
--------+--------+-----------
ra | real |
dec | real |
bmag | real |
rmag | real |
ipix | bigint |
errbox | box |
Indexes:
"box_ind" rtree (errbox)
"ipix_ind" btree (ipix) CLUSTER
"radec_idx1" btree (ra,dec)
Database size:
We were able to load database, create indices, run vacuum in about 20 hours, which is rather good timing for our resources.
We plot time (ms) vs the number of fetched tuples in logarithmic axes.
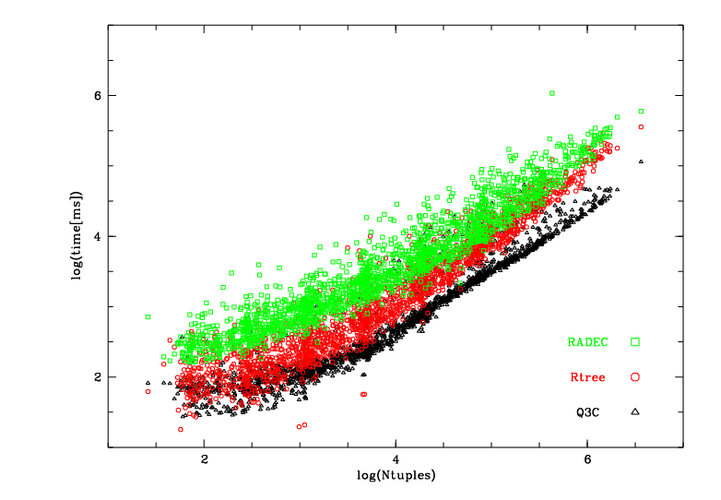
Database performance for very large data sets (much more than RAM available) is often characterized in terms of input/output operations (tuples, index block reads and usage of cache in database buffers).
The figures below show the differences in disk I/O for different sky indexing schemes.
The number of index blocks read during the queries versus number of fetched tuples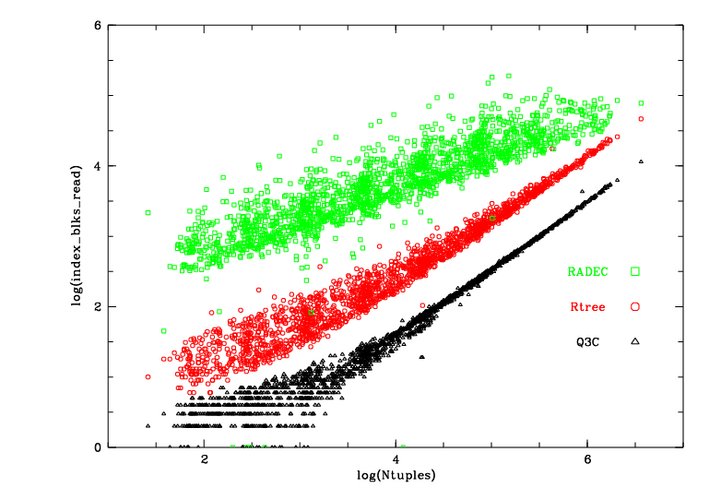 |
The number blocks read from the heap during the queries versus number of returned tuples
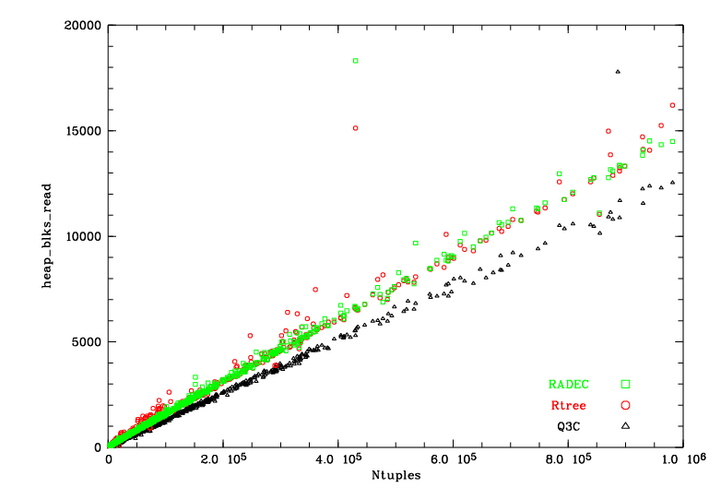 |
See also SphereLinks

